



NVIDIA GEFORCE RTX 2080 TI GRÁFICOS TI |, NVIDIA OFICIAL RTX 2080 TI, 2080 y 2070 especificaciones, precio, fecha de lanzamiento | Gamersnexus – Gaming PC compilaciones y puntos de referencia de hardware
Fecha de lanzamiento de 2080 TI
Sin embargo, el aspecto más grande de esa noticia es que la interconexión de GPU coherente de caché de Nvidia, NVLink, llegará a tarjetas de consumo. Las tarjetas GEFORCE GTX implementarán SLI sobre NVLink, con 2 canales NVLink ejecutados entre cada tarjeta. En un ancho de banda combinado de 50 GB/seg de Full-Duplex, lo que significa que hay 50 GB de ancho de banda disponible en cada dirección, esta es una actualización importante sobre el enlace HB-SLI anterior de NVIDIA. Esto está en la cima de los otros beneficios de la característica de NVLink, particularmente la coherencia de caché. Y todo esto llega en un momento importante, ya que los requisitos de ancho de banda entre GPU siguen aumentando con cada generación.
Tarjeta gráfica NVIDIA GEFORCE RTX 2080 TI TI
Modded GeForce RTX 2080 TI admite 22 GB de memoria GDDR6
Teclab rompe la barrera de reloj GPU de 3GHz con GeForce RTX 2080 TI
Se rumoreaba que NVIDIA retirará GeForce RTX 2080 (TI/Super) y GeForce RTX 2070 (Super) Tarjetas gráficas pronto
MSI Outs GeForce RTX 2080 TI Gaming Z con 16 GBPS GDDR6 Memoria
NVIDIA anuncia GeForce RTX 2080 TI “Cyberpunk 2077 Edition”
ASUS muestra a GeForce RTX 2080 Ti Rog Strix White Edition
Gigabyte lanza Aorus Gaming Box con RTX 2080 TI
Galax GeForce RTX 2080 TI HOF Edición del décimo aniversario manchada
MSI RTX 2080 TI Lightning Edición del décimo aniversario en la foto
MSI TEASS GEFORCE RTX 2080 TI Lightning Edición del décimo aniversario
(PR) MSI anuncia GeForce RTX 2080 TI Lightning Z
Evga GeForce RTX 2080 TI Kingpin Edition es un híbrido
MSI GeForce RTX 2080 TI Lightning en la foto
ASUS muestra ROG GEFORCE RTX 2080 TI Matrix
Colorida GeForce RTX 2080 Ti Igame Kudan Smiles para cámara
MSI se burla del fibra de carbono GeForce RTX 2080 TI Lightning Z
Zotac GeForce RTX 2080 Ti Arcticstorm para debutar en CES 2019
MSI GeForce RTX 2080 TI Lightning Z PCB en la foto
Colorido lanzamientos GeForce RTX 2080 (TI) RNG Edition con LCD a todo color
(PR) Inno3d anuncia la serie GeForce RTX Ichill Frostbite
Evga se burla de GeForce RTX 2080 TI Kingpin
Gigabyte Preparación de GeForce RTX 2080 Ti Aorus Turbo
Nvidia Bundles Battlefield V con GeForce RTX gratis
(PR) Manli anuncia GeForce RTX 2080 TI y 2070 con ventilador de ventilador
Nuevo informe de la tarjeta #21: La edición RTX RGB
Inno3d convierte la tarjeta GeForce RTX en el árbol de Navidad Giant RGB
MSI anuncia GeForce RTX 2080 (TI) Sea Hawk (EK) X Serie
Gigabyte se burla de GeForce RTX 2080 (TI) Aorus Graphics Card
NVIDIA GEFORCE RTX 2080 TI & RTX 2080 REDONTA REVISIÓN
TechPowerUp explica la diferencia entre las variantes de GPU de Turing A y no A
NVIDIA GEFORCE RTX 2080 TI y RTX 2080 RENDIMIENTO “Oficial” presentado
Las nuevas características de la arquitectura nvidia turing
Nvidia Changes GeForce RTX 2080 Revisiones Fecha hasta el 19 de septiembre
NVIDIA GEFORCE RTX 2080 Las revisiones se ponen en marcha el 17 de septiembre
EVGA presenta modelos Hydro Copper and Hybrid GeForce RTX
- 2025 GeForce 50 TBA
- 2023 GeForce 40 Mobile
- 2022 GeForce 40
- 2021 GeForce 30 Mobile
- 2020 GeForce 30
- 2019 GeForce 16
- 2019 GeForce 16 Mobile
- 2018 GeForce 20
- 2018 GeForce 20 Mobile
- 2016 GeForce 10
- 2016 GeForce 10 Mobile
- 2014 GeForce 800 Mobile
- 2014 GeForce 900
- 2014 GeForce 900 Mobile
- 2013 GeForce 700
- 2013 GeForce 700 Mobile
- 2012 GeForce 600
- Centro de datos / Tesla
- Tegra
- Estación de trabajo / Quadro
- GeForce MX
- Titan rtx
- GeForce RTX 2080 TI
- GeForce RTX 2080 Super
- GeForce RTX 2080
- GeForce RTX 2070 Super
- GeForce RTX 2070
- GeForce RTX 2060 Super
- GeForce RTX 2060 12GB
- GeForce RTX 2060
- GeForce MX250
- Apilamiento 3D
- Accesorios
- Anuncios
- Manzana
- BRAZO
- Inteligencia artificial
- Industria automotriz
- Puntos de referencia
- Negocios y mercados
- Gráficos chinos
- Conceptos
- Conectividad
- Creación de contenido
- Tecnología de enfriamiento
- Criptomoneda
- Proyectos personalizados
- Ofertas
- Pantallas y monitores
- Eventos
- GPU y recintos externos
- Revisiones externas
- Overclocking extremo
- Resultados financieros
- Fuseles
- Paquetes de juegos y ofertas
- Requisitos de juego
- Transmisión de juegos
- Juegos
- Consolas de juego
- Hardware de juego
- Gráficos
- API gráficos
- Entrevistas
- Linux
- Tecnología de memoria
- PC MINI/SFF/NUC
- Dispositivos móviles
- Modificación
- Placas base
- Cuadernos
- Patentes e investigación
- Casos de PC
- PCI-Express
- Gente
- Fuentes de alimentación
- Sistemas prebuidados
- RISC-V
- Seguridad
- Software y conductores
- Almacenamiento
- súper resolución
- Supercomputación (HPC)
- Codificación de video
- Historias virales
- Realidad virtual
- Refrigeración por agua
- 2025 Radeon 8000 TBA
- 2023 Radeon 7000 Mobile
- 2022 Radeon 7000
- 2021 Radeon 6000 Mobile
- 2020 Radeon 6000
- 2019 Radeon 5000
- 2019 Radeon 5000 Mobile
- 2017 Radeon 500
- 2017 Radeon 500 Mobile
- Radeon 400 2016
- 2016 Radeon 400 Mobile
- 2015 Radeon 300
- 2015 Radeon 300 Mobile
- 2014 Radeon 200 Mobile
- 2013 Radeon 200
- Instinto de Radeon
- Radeon Pro
- Compute de blockchain
- 2025 GeForce 50 TBA
- 2023 GeForce 40 Mobile
- 2022 GeForce 40
- 2021 GeForce 30 Mobile
- 2020 GeForce 30
- 2019 GeForce 16
- 2019 GeForce 16 Mobile
- 2018 GeForce 20
- 2018 GeForce 20 Mobile
- 2016 GeForce 10
- 2016 GeForce 10 Mobile
- 2014 GeForce 800 Mobile
- 2014 GeForce 900
- 2014 GeForce 900 Mobile
- 2013 GeForce 700
- 2013 GeForce 700 Mobile
- 2012 GeForce 600
- Centro de datos / Tesla
- Tegra
- Estación de trabajo / Quadro
- GeForce MX
- 2025 arco druid tba
- 2024 arco Celestial TBA
- 2023 arc battlemage tba
- 2022 Arc Alchemist
- 2022 Intel Data Center HPC TBA
- 2021 Centro de datos Intel HP TBA
- 2020 Intel XE-LP
- ARC Pro
Fecha de lanzamiento de 2080 TI
NVIDIA oficial RTX 2080 TI, 2080 y 2070 especificaciones, precio, fecha de lanzamiento
Por Steve Burke publicado el 20 de agosto de 2018 a las 3:00 p.m

Actualizar: Se agregó una corrección para los números de núcleo SM / CUDA, ahora que se han filtrado detalles completos.
Nvidia anunció sus nuevas tarjetas de video Turing para juegos hoy, incluidos RTX 2080 TI, RTX 2080 y RTX 2070. Las tarjetas avanzan con una arquitectura Volta actualizada pero familiar, con algunos cambios en el SMS y la memoria. El nuevo barco RTX 2080 y 2080 TI con tarjetas de referencia primero, y tarjetas de socio en gran parte al mismo tiempo (con algunos modelos más avanzados que se producen más de 1 mes después), Dependiendo de qué compañero sea. Los socios de la junta no recibieron precios ni nombres de tarjetas hasta el mismo tiempo que los medios, por lo que espere retrasos en soluciones personalizadas. Tenga en cuenta que originalmente estábamos escuchando una latencia de 1-3 meses en las tarjetas de asociación, pero eso parece ser solo para modelos avanzados que ahora están entrando en producción. La mayoría de los modelos Tri-Fan deben estar disponibles en la misma fecha.
Otro punto importante de consideración es la decisión de Nvidia de usar una tarjeta de referencia de doble axil, eliminando gran parte del valor de las tarjetas de socios en la gama baja. Alejarse de las tarjetas de referencia del ventilador y hacia las tarjetas de doble fan afectará más inmediatamente a los socios de la junta, algo que podría conducir a una lenta rastreo de Nvidia expandiendo sus ventas directas a consumo y socios evitando. El RTX 2080 TI tendrá un precio de $ 1200 y se lanzará el 20 de septiembre, con el 2080 a $ 800 (y el 20 de septiembre), y el 2070 a $ 600 (fecha de lanzamiento de TBD).
NVIDIA RTX 2080 TI y 2080 especificaciones
Uno de los mayores errores que cometen las personas al comparar nuevas GPU es hablar sobre “Core Count.”Esto es erróneo por algunas razones, una de las cuales es que el rendimiento del núcleo para el núcleo no es una arquitectura intermedia idéntica. Desde Kepler hasta Pascal, hubo ganancias más del 30% para la eficiencia general de rendimiento por vatio, y simplemente dibujar una comparación lineal entre los recuentos de núcleo no acomoda esto. Además, los núcleos de Cuda no son en realidad núcleos, de todos modos: son unidades de punto flotante. Un SM sería más similar a un núcleo por definiciones estándar, que requieren que un núcleo sea capaz de obtener y decodificar instrucciones, ejecutarlas, leer y escribir datos hacia y desde registros y caché, y los resultados de la computación. Las unidades de punto flotante de Nvidia pueden calcular los resultados, pero no pueden hacer muchas de las otras cosas.
El objetivo de decir todo esto es que un Pascal estricto vs. La comparación del núcleo de Turing debe tener en cuenta las diferencias arquitectónicas que podrían cambiar qué tan bien funciona un “núcleo” para comenzar con. La gente cayó en la misma trampa la última vez.
NVIDIA RTX 2080 TI, 2080 y 2070 FUNDERS EDITION SECCIONES
Las nuevas unidades de punto flotante RTX 2080 TI de NVIDIA 4352, con el RTX 2080 Non-Ti Hosting 2944 FPUS. Nvidia se adhiere a 64 fpus por multiprocesador de transmisión, que puso el 2080 Ti a 68 SMS, con el 2080 a 46 SMS. Nvidia ha reelaborado la arquitectura SM para esta GPU, por lo que todavía no estamos positivos en todos los detalles más finos.
Las nuevas GPU también se mueven a GDDR6, un cambio esperado. En la actualidad, GDDR6 tiene aproximadamente un costo de licenciatura 20% más alto que GDDR5, pero ese costo caerá con el tiempo. GDDR6 permite un rendimiento mínimo de 14 Gbps por PIN en el RTX 2080 y 2080 TI, un impulso notable sobre el rendimiento de 8 Gbps y 10 Gbps en generaciones anteriores. GDDR6 también puede superar hasta 16 Gbps por pin, pero no hay una promesa inmediata de eso para las nuevas GPU. Todavía no estamos seguros del impacto de la sincronización de la memoria de GDDR6. El 2080 TI organizará 11 GB de GDDR6 en un bus de memoria de 352 bits, con un ancho de banda de memoria en el vecindario de 620 GB/s. El RTX 2080 alojará 8 GB de GDDR6 en una interfaz de 256 bits y, por lo tanto, permitirá el ancho de banda de memoria de 448 GB/S.
| RTX 2080 TI | RTX 2080 | RTX 2070 | |
| FP32 FPU (“CUDA CORES”) | 4352 | 2944 | 2304 |
| Transmisión de multiprocesadores | 68 | 46 | 36 |
| Reloj / Reloj Core Boost | 1350/1545 Fe: 1635MHz | 1515/1710 Fe: 1800MHz | 1410/1620 Fe: 1710MHz |
| interfaz de memoria | 352 bits | De 256 bits | De 256 bits |
| Capacidad de memoria | 11 GB | 8GB | 8GB |
| Velocidad GDDR6 | 14GBPS | 14GBPS | 14GBPS |
| ancho de banda de memoria | 616GB/s | 448GB/s | 448GB/s |
| SLI | Nvlink 2-vías | Nvlink 2-vías | TBD |
| TDP | ~ 265 ~ 285W | ~ 250-260W | 175-185W |
| Precio | $ 1,200 O $ 1000* | $ 800 O $ 700* | $ 600 O $ 500* |
| Fecha de lanzamiento | Septiembre. 20, 2018 | Septiembre. 20, 2018 | TBD |
*Fuente de precios: sitio web de NVIDIA. NOTA: También hemos escuchado que los precios (tal vez para las tarjetas que no son FE? ¿O solo hay una falta de comunicación dentro de Nvidia??) también podría ser de $ 500 para el 1070, $ 700 para el 2080 y $ 1000 para el 2080 TI. Creemos que esto podría ser Fe vs. Referencia, pero también podría ser una falta de comunicación por parte de los equipos de Nvidia. No claro en este momento.
NVIDIA anuncia la serie GeForce RTX 20: RTX 2080 TI y 2080 en septiembre. 20th, RTX 2070 en octubre

La nota clave de Nvidia Gamescom 2018 acaba de terminar, y como muchos han esperado desde que se anunció el mes pasado, Nvidia se está preparando para lanzar su próxima generación de hardware de GeForce. Anunciado en el evento y saliendo a la venta a partir del 20 de septiembre es la serie GeForce RTX 20 20 de NVIDIA, que está sucediendo a la actual serie GeForce GTX 10 con motor PASCAL. Basado en la nueva arquitectura de GPU Turing de NVIDIA y basada en el proceso “FFN” de 12 nm de TSMC, NVIDIA tiene objetivos elevados, buscando impulsar un cambio de paradigma completo en cómo se representan los juegos y cómo se evalúan las tarjetas de video de PC. El CEO Jensen Huang ha llamado a la arquitectura de GPU más importante de Turing Nvidia desde la arquitectura Tesla GPU de 2006 (G80 GPU), y desde el punto de vista de las características está claro que no está exagerando los asuntos.
Como es tradicionalmente el caso, las primeras cartas que salen del establo de Nvidia son las cartas de gama alta. Pero en un descanso bastante considerable de la tradición no solo vamos a obtener las tarjetas X80 y X70 en el lanzamiento, sino también la tarjeta X80 Ti. Es decir, la GeForce RTX 2080 TI, RTX 2080 y RTX 2070 llegarán a las calles dentro de un mes de diferencia. La pila de productos de Nvidia permanece sin cambios aquí, por lo que RTX 2080 TI sigue siendo su tarjeta insignia, mientras que RTX 2080 es su tarjeta de alta gama, y luego RTX 2070 la tarjeta ligeramente más barata para atraer a los entusiastas de los atracos sin romper el banco.
Las tres tarjetas se lanzarán en los próximos dos meses. Primero estará el RTX 2080 TI y RTX 2080, que se lanzará el 20 de septiembre . El RTX 2080 TI comenzará en $ 999 para tarjetas de socio, mientras que el RTX 2080 comenzará en $ 699. Mientras tanto, el RTX 2070 se lanzará en algún momento de octubre, con tarjetas de socios que comienzan en $ 499. Sobre una base histórica, todos estos precios son más altos que la última generación entre $ 120 y $ 300. Mientras tanto, las propias tarjetas de edición de fundadores de calidad de referencia de Nvidia están una vez más, y esas llevarán una prima de $ 100 a $ 200 sobre el precio de referencia.
Desafortunadamente, Nvidia ya está tomando pedidos anticipados aquí, por lo que los consumidores son esencialmente obligados a hacer una “compra ciega” si quieren enganchar una tarjeta del primer lote. NVIDIA ha ofrecido sorprendentemente poca información sobre el rendimiento y sugerimos esperar revisiones confiables de terceros (i.mi. nosotros), sin embargo, tengo que admitir que no me imagino que habrá muchas acciones disponibles para cuando las revisiones salgan a las calles.
| Comparación de especificaciones de Nvidia GeForce | ||||||
| RTX 2080 TI | RTX 2080 | RTX 2070 | GTX 1080 | |||
| Núcleos de cuda | 4352 | 2944 | 2304 | 2560 | ||
| Reloj de núcleo | 1350MHz | 1515MHz | 1410MHz | 1607MHz | ||
| Reloj de impulso | 1545MHz | 1710MHz | 1620MHz | 1733MHz | ||
| Reloj de la memoria | 14GBPS GDDR6 | 14GBPS GDDR6 | 14GBPS GDDR6 | 10GBPS GDDR5X | ||
| Ancho del bus de memoria | 352 bits | De 256 bits | De 256 bits | De 256 bits | ||
| Vram | 11 GB | 8GB | 8GB | 8GB | ||
| Perfor de precisión única. | 13.4 tflops | 10.1 tflops | 7.5 tflops | 8.9 tflops | ||
| Tensor perfor. | 440T OPS (Int4) | ? | ? | N / A | ||
| Rayo perf. | 10 grises/s | 8 grises/s | 6 grises/s | N / A | ||
| “RTX-OPS” | 78T | 60T | 45t | N / A | ||
| TDP | 250W | 215W | 175W | 180W | ||
| GPU | Big Turing | Turing sin nombre | Turing sin nombre | GP104 | ||
| Recuento de transistores | 18.6b | ? | ? | 7.2b | ||
| Arquitectura | Turing | Turing | Turing | Pascal | ||
| Proceso de manufactura | TSMC 12NM “FFN” | TSMC 12NM “FFN” | TSMC 12NM “FFN” | TSMC 16NM | ||
| Fecha de lanzamiento | 20/09/2018 | 20/09/2018 | 10/2018 | 27/05/2016 | ||
| Precio de lanzamiento | MSRP: $ 999 Fundadores $ 1199 | MSRP: $ 699 Fundadores $ 799 | MSRP: $ 499 Fundadores $ 599 | MSRP: $ 599 Fundadores $ 699 | ||
Arquitectura de Turing de Nvidia: RT y núcleos de tensor
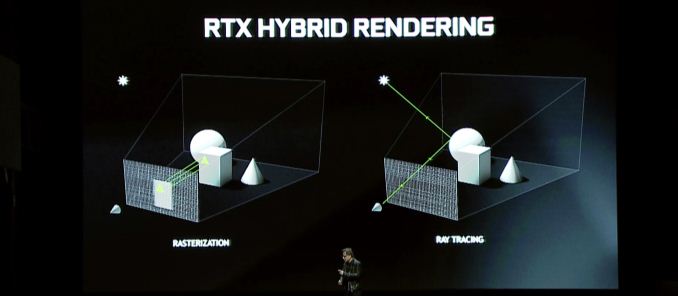
Entonces, ¿qué trae Turing a la mesa?? La característica de marquesina en todos los ámbitos es la representación híbrida, que combina el trazado de rayos con rasterización tradicional para explotar las fortalezas de ambas tecnologías. Este anuncio es esencialmente una continuación del anuncio RTX de NVIDIA de principios de este año, por lo que si pensabas que el anuncio era un poco escaso, bueno, aquí está el resto de la historia.
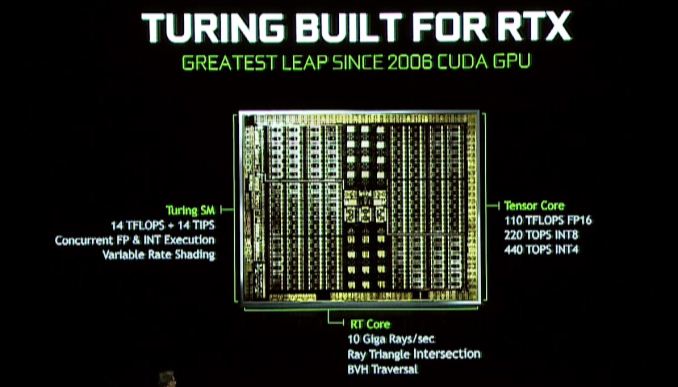
El gran cambio aquí es que Nvidia incluirá aún más hardware de rastreo de rayos con Turing para ofrecer una aceleración de trazado de rayos de hardware más rápido y eficiente. Nuevo en la arquitectura de Turing es lo que Nvidia está llamando un núcleo RT, cuyos fundamentos no estamos completamente informados en este momento, sino que sirven como procesadores de rastreo de rayos dedicados. Estos bloques de procesadores aceleran tanto las verificaciones de intersección del triángulo de rayos como la manipulación de la jerarquía de volumen delimitador (BVH), siendo esta última una estructura de datos muy popular para almacenar objetos para la trazado de rayos.
Nvidia afirma que la parte de GeForce RTX más rápida puede emitir 10 mil millones (GIGA) rayos por segundo, que en comparación con el Pascal no acelerado es una mejora de 25x en el rendimiento del rastreo de rayos.
La arquitectura de Turing también lleva los núcleos de tensor de Volta, y de hecho, estos incluso se han mejorado sobre Volta. Los núcleos de tensor son un aspecto importante de las iniciativas múltiples de Nvidia. Además de acelerar el rastreo de rayos, la otra herramienta de Nvidia en su bolsa de trucos es reducir la cantidad de rayos requeridos en una escena mediante el uso de AI Denoising para limpiar una imagen, que es algo que los núcleos de tensor se destacan. Por supuesto, esa no es la única característica de los núcleos de tensor: todo el imperio de redes neuronales de AI/NVIDIA está casi construido en ellos, por lo que, si bien no es un enfoque principal para la multitud de Gamescom, esto también confirma que el hardware de redes neuronales más potentes de Nvidia vendrá a una gama más amplia de GPU.
Mirando la representación híbrida en general, es interesante que a pesar de estas aceleraciones individuales, las promesas generales de rendimiento de Nvidia no son tan extremas. En total, la compañía promete un impulso de rendimiento de 6x versus Pascal, y esto no especifica en qué partes. El tiempo dirá si incluso esta es una evaluación realista, ya que incluso con los núcleos RT, el rastreo de rayos en general sigue siendo un recurso cerebro de recursos.
En cuanto a las cosas de los juegos en particular, los beneficios de la representación híbrida son potencialmente significativos, pero dependerá en gran medida de cómo los desarrolladores elijan usarlo. Desde el punto de vista del rendimiento, no estoy seguro de que haya mucho que decir aquí, y eso se debe a que el trazado de rayos y la representación híbrida son en última instancia características para mejorar la calidad de la representación, no mejorar el rendimiento de los algoritmos de hoy en día. De acuerdo, si intentas hacer rastreo de rayos en las GPU de hoy en día, sería extremadamente lento, y como resultado, pero no usa sistemas de rastreo de ruta lenta en el hardware actual por esta razón. Por lo tanto, la representación híbrida se trata de reemplazar las aproximaciones y hacks de la tecnología de rasterización actual con métodos de representación más precisos. En otras palabras, menos “fingirlo” y más “haciéndolo.”

Esos beneficios de calidad, a su vez, generalmente se agrupan alrededor de la iluminación, las sombras y los reflejos. Las tres características se basan inherentemente en las propiedades de la luz, que en términos simplistas se mueven como un rayo, y que hasta ahora varios algoritmos han estado fingiendo el trabajo involucrado o las escenas de “pre-hornear” de antemano. Y aunque los algoritmos actuales son bastante buenos, todavía no están cerca de precisos. Entonces hay espacio claro para mejorar.


Nvidia por su parte está particularmente lanzando la iluminación global, que es una de las tareas más difíciles. Sin embargo, hay otros métodos de iluminación que también se benefician, sin mencionar los reflejos y las sombras de esos objetos iluminados. Y sinceramente, aquí es donde las palabras son una herramienta pobre; Es difícil describir cómo una sombra rastreada se ve mejor que una sombra falsa con PCSS, o iluminación en tiempo real sobre iluminación preconsada. Por eso Nvidia, la compañía de tarjetas de video, va a presionar los aspectos visuales de todo esto más duro que nunca.
En general, la representación híbrida es la característica de linchpin de la serie GeForce RTX 20. Pasando sus presentaciones de Gamescom y Siggraph, está claro que Nvidia ha invertido mucho en el campo, y que han apostado el éxito de la marca GeForce en los próximos años en esta tecnología. Los núcleos RT y los núcleos de tensor son hardware de funciones semi fijadas; No pueden usarse para la rasterización, y los transistores asignados a ellos son transistores que podrían haberse dedicado a más hardware de rasterización de otra manera. Entonces, Nvidia ha hecho un movimiento increíblemente significativo aquí en términos de costo de oportunidad al seguir la ruta de representación híbrida en lugar de construir un pascal más grande.
Como resultado, Nvidia está intentando un cambio de paradigma en la representación de los consumidores, uno que realmente solo vemos antes con la introducción de Pixel y Vertex Shaders (DX8 y DX9 ERA Tech) en 2001 y 2002. Es por eso que la iniciativa DirectX Raytracing (DXR) de Microsoft es tan importante, al igual que las otras iniciativas de desarrolladores y consumidores de NVIDIA. Nvidia necesita vender consumidores y desarrolladores por igual sobre esta visión de mezclar rasterización con rastreo de rayos para proporcionar una mejor calidad de imagen. Y más que eso, necesitan aliviar a los desarrolladores en la idea de trabajar con unidades de función fija más especializadas a medida que la ley de Moore continúa disminuyendo la velocidad y el hardware de la función fija se convierte en un medio para lograr una mayor eficiencia.
Nvidia no ha apostado a la granja en la representación híbrida, pero nunca han intentado mover el mercado de esta manera. Entonces, si parece que Nvidia está hiper centrado en la representación híbrida y el trazado de rayos, eso es porque están. Es su visión del futuro, y ahora necesitan tener a todos los demás a bordo.
Turing SM: Dediced int nores, caché unificado, sombreado de tasa variable
Junto con los núcleos de RT y tensor dedicados, el multiprocesador de transmisión de arquitectura de Turing (SM) también está aprendiendo algunos trucos nuevos. En particular aquí, está heredando uno de los cambios más novedosos de Volta, que vieron a los núcleos enteros separados en sus propios bloques, en lugar de ser una faceta de los núcleos de punto flotante. La ventaja aquí, al menos tanto como vimos en Volta, es que acelera la generación de direcciones y el rendimiento de la multiplica fusionada (FMA), aunque al igual que con muchos aspectos de Turing, es probable que haya más ser utilizado para) de lo que estamos viendo hoy.
El Turing SM también incluye lo que Nvidia está llamando una “arquitectura de caché unificado.”Como todavía estoy esperando diagramas oficiales de SM de Nvidia, no está claro si este es el mismo tipo de unificación que vimos con Volta, donde el caché L1 se fusionó con la memoria compartida, o si Nvidia ha ido un paso más allá. En cualquier caso, Nvidia dice que ofrece el doble de ancho de banda de la “generación anterior”, lo cual no está claro si Nvidia significa Pascal o Volta (con este último es más probable).
Finalmente, también escondido en el comunicado de prensa de Siggraph Turing se menciona el soporte para el sombreado de la velocidad variable. Esta es una técnica de representación gráfica relativamente joven y futura sobre la que hay información limitada (especialmente en cuanto a cómo exactamente Nvidia lo está implementando). Pero en un nivel muy alto suena como la próxima generación de la tecnología de sombreado de múltiples resentos de NVIDIA, que permite a los desarrolladores hacer diferentes áreas de una pantalla a varias resoluciones efectivas, para concentrar la calidad (y el tiempo de representación) en las áreas donde es el mas beneficioso.
Alimentar a la bestia: soporte GDDR6
Como la memoria utilizada por las GPU es desarrollada por empresas externas, no hay grandes secretos aquí. El Jedec y sus 3 miembros Big 3 Samsung, SK Hynix y Micron, han estado desarrollando la memoria GDDR6 como el sucesor de GDDR5 y GDDR5X, y Nvidia HA confirmó que Turing lo apoyará. Dependiendo del fabricante, GDDR6 de primera generación generalmente se promueve como que ofrece hasta 16 Gbps por pin de ancho de banda de memoria, que es 2x que de las tarjetas GDDR5 de generación tardía de NVIDIA, y un 40% más rápido que las tarjetas GDDR5X más recientes de NVIDIA.
| Matemáticas de memoria de GPU: GDDR6 vs. HBM2 VS. Gddr5x | ||||||||
| Nvidia GeForce RTX 2080 TI (GDDR6) | Nvidia GeForce RTX 2080 (GDDR6) | Nvidia titan v (HBM2) | Nvidia titan xp | Nvidia GeForce GTX 1080 TI | Nvidia GeForce GTX 1080 | |||
| Capacidad total | 11 GB | 8 GB | 12 GB | 12 GB | 11 GB | 8 GB | ||
| B/w por alfiler | 14 GB/s | 1.7 GB/s | 11.4 Gbps | 11 Gbps | ||||
| Capacidad de chip | 1 GB (8 GB) | 4 GB (32 GB) | 1 GB (8 GB) | |||||
| No. Chips/kgsds | 11 | 8 | 3 | 12 | 11 | 8 | ||
| B/w por chip/pila | 56 GB/s | 217.6 GB/s | 45.6 GB/s | 44 GB/s | ||||
| Ancho de bus | 352 bits | De 256 bits | 3092 bit | 384 bits | 352 bits | De 256 bits | ||
| Total B/W | 616 GB/s | 448GB/s | 652.8 GB/s | 547.7 GB/s | 484 GB/s | 352 GB/s | ||
| Voltaje de DRAM | 1.35 V | 1.2 V (?) | 1.35 V | |||||
En relación con GDDR5X, GDDR6 no es un paso tan grande como algunas generaciones de memoria pasadas, ya que muchas de las innovaciones de GDDR6 ya estaban horneadas en GDDR5X. Sin embargo, junto con HBM2 para casos de uso de muy alta gama, se espera que se convierta en el recuerdo de la red de la industria de la GPU. Los cambios principales aquí incluyen voltajes operativos más bajos (1.35V), e internamente la memoria ahora se divide en dos canales de memoria por chip. Para un chip estándar de 32 bits de ancho, esto significa un par de canales de memoria de 16 bits, para un total de 16 canales de este tipo en una tarjeta de 256 bits. Si bien esto a su vez significa que hay una gran cantidad de canales, las GPU también están bien posicionadas para aprovecharlo, ya que son dispositivos masivamente paralelos para empezar.

Nvidia por su parte ha confirmado que las primeras tarjetas RTX de GeForce ejecutarán su GDDR6 a 14 Gbps, que es la calificación de velocidad más rápida ofrecida por todos los 3 miembros de los 3 grandes. Sabemos que NVIDIA está utilizando exclusivamente el GDDR6 de Samsung para sus tarjetas Quadro RTX, presumiblemente porque necesitan la densidad, sin embargo, para las tarjetas GeForce RTX, el campo debe estar abierto a todos los fabricantes de memoria. Aunque a largo plazo, esto deja dos vías abiertas a tarjetas de mayor capacidad: ya sea moverse hasta 16 GB de chips de densidad o ir al clamshell con las chips de 8 GB que están usando ahora.
Odds & Ends: Nvlink SLI, VirtUlallink y 8K HEVC
Si bien esto no se mencionó en la presentación de Nvidia Gamescom, el sitio web de la Serie GeForce 20 de NVIDIA confirma que SLI volverá a estar disponible para algunas tarjetas GeForce RTX de alta gama. Específicamente, tanto el RTX 2080 TI como RTX 2080 admitirán SLI. Mientras tanto, el RTX 2070 no admitirá SLI; Esto es una desviación del 1070 que lo ofreció.
Sin embargo, el aspecto más grande de esa noticia es que la interconexión de GPU coherente de caché de Nvidia, NVLink, llegará a tarjetas de consumo. Las tarjetas GEFORCE GTX implementarán SLI sobre NVLink, con 2 canales NVLink ejecutados entre cada tarjeta. En un ancho de banda combinado de 50 GB/seg de Full-Duplex, lo que significa que hay 50 GB de ancho de banda disponible en cada dirección, esta es una actualización importante sobre el enlace HB-SLI anterior de NVIDIA. Esto está en la cima de los otros beneficios de la característica de NVLink, particularmente la coherencia de caché. Y todo esto llega en un momento importante, ya que los requisitos de ancho de banda entre GPU siguen aumentando con cada generación.

Ahora la gran pregunta es si esto revertirá el declive continuo de SLI, y en este momento estoy adoptando un enfoque algo pesimista, pero estoy ansioso por escuchar más de Nvidia. 50GB/seg es una gran mejora sobre HB-SLI, sin embargo, todavía es solo una fracción de los 448 GB/seg (o más) del ancho de banda de memoria local disponible para una GPU. Entonces, por sí solo, no soluciona los problemas que han perseguido la representación de múltiples GPU, ya sea con sincronización de AFR o división de carga de trabajo efectiva. En ese sentido, es probable que NVIDIA no admite NVLink SLI en el RTX 2070.
Mientras tanto, los jugadores son algo nuevo que esperar para la realidad virtual, con la adición de soporte de virtualLink. El modo alternativo USB tipo C se anunció el mes pasado y admite 15W+ de potencia, 10 Gbps de USB 3.1 Gen 2 Datos y 4 carriles del video HBR3 de Displayport en todo un solo cable. En otras palabras, es un displayport 1.4 Conexión con datos adicionales y energía que está destinada a permitir que una tarjeta de video conduzca directamente un auricular VR. El estándar está respaldado por NVIDIA, AMD, Oculus, Valve y Microsoft, por lo que las tarjetas GeForce RTX serán las primeras de lo que esperamos serán en última instancia una serie de productos que respalden el estándar.
| Modos alternativos USB tipo-C | ||||||
| Virtuallink | Visualización (4 carriles) | Visualización (2 carriles) | Base USB-C | |||
| Video de ancho de banda (Raw) | 32.4Gbps | 32.4Gbps | dieciséis.2GBPS | N / A | ||
| USB 3.X ancho de banda de datos | 10 Gbps | N / A | 10 Gbps | 10 Gbps + 10 Gbps | ||
| Pares de carril de alta velocidad | 6 | 4 | ||||
| Máximo poder | Obligatorio: 15W Opcional: 27W | Opcional: hasta 100W | ||||
Finalmente, mientras Nvidia solo mencionó brevemente el tema, sabemos que su bloque de codificadores de video, NVENC, ha sido actualizado para Turing. La última iteración de NVENC agrega específicamente el soporte para la codificación de 8k HEVC. Mientras tanto, Nvidia también ha podido sintonizar aún más la calidad de su codificador, lo que les permite alcanzar una calidad similar a antes con una tasa de bits de video 25% más baja.